
Data Tools: Assessing Datasets with Data Nutrition Labels
At-a-glance "ingredients list" and snapshot of dataset quality and composition — designed to help data teams assess fit before EDA and encourage responsible documentation by dataset creators.

This is part of Data Tools You Can Use, a Data x Direction series exploring practical tools that help data scientists and leaders build more responsible, reproducible, and ethical data projects. The goal is to bridge the gap between theoretical or academic frameworks and the real-world tools data teams actually rely on.
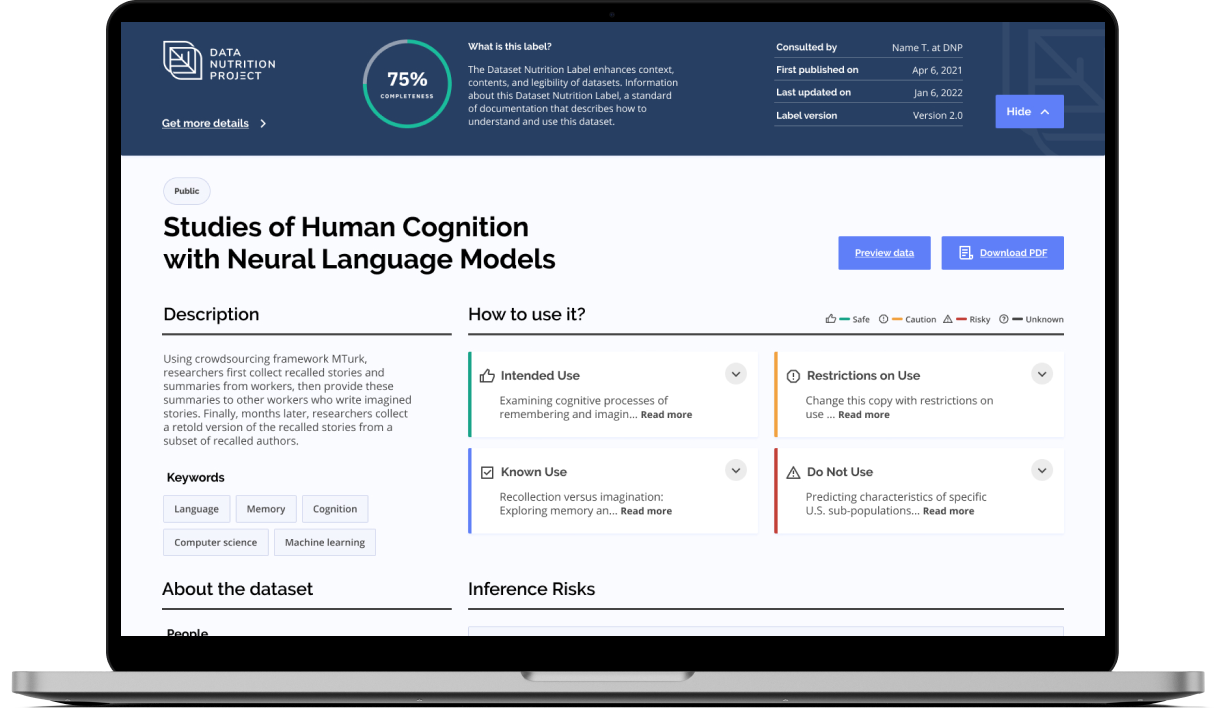
In our data-dependent world, ensuring the quality and integrity of datasets is more challenging than simply checking technical metrics. Hidden biases, unclear use parameters, decontextualized feature selection, and unrepresentative samples can undermine downstream quality and decisions if left unchecked - or unconsidered outright. The Data Nutrition Project proposes a method to reveal more about the quality of a dataset’s “ingredients,” offering a standardized snapshot that goes beyond traditional quality checks.
Founded in 2018 through the Assembly Fellowship, The Data Nutrition Project takes inspiration from nutritional labels on food, aiming to build labels that highlight the key ingredients in a dataset such as metadata and demographic representation, as well as unique or anomalous features regarding distributions, missing data, and comparisons to other "ground truth" datasets. [Source]
Project Lead and Co-Founder Kasia Chmielinski gives a broad introduction in this associated TED talk:
What Are Data Nutrition Labels?
Many data ethics conversations focus on post-hoc bias detection — fixing models after they’re deployed. Data Nutrition Labels shifts this focus, encouraging teams to facilitate proper use and prevent ethical risks at the point of data sourcing and design, before modeling starts; thus labels as enhancing a potential users ability to “interrogate” the dataset and discern data quality or applicability.

Inspired by food nutrition labels, Data Nutrition Labels are designed to provide an overview of a dataset’s key characteristics:
Provenance: Outlines where the data originates and the context behind its collection. (See IBM’s intro to Data Provenance)
Coverage: Details which populations, timeframes, and geographies are included, while noting potential gaps or underrepresentation.
Limitations: Identifies known biases, sampling issues, and consent-related concerns.
Intended Use Cases: Indicates when the data may be fit for purpose and highlights situations where it might be unsuitable.
This structured summary aims to enhance awareness of the ethical and representational dimensions of data before the modeling process begins. Yet, while informative, these labels do not capture every nuance of data quality or context.
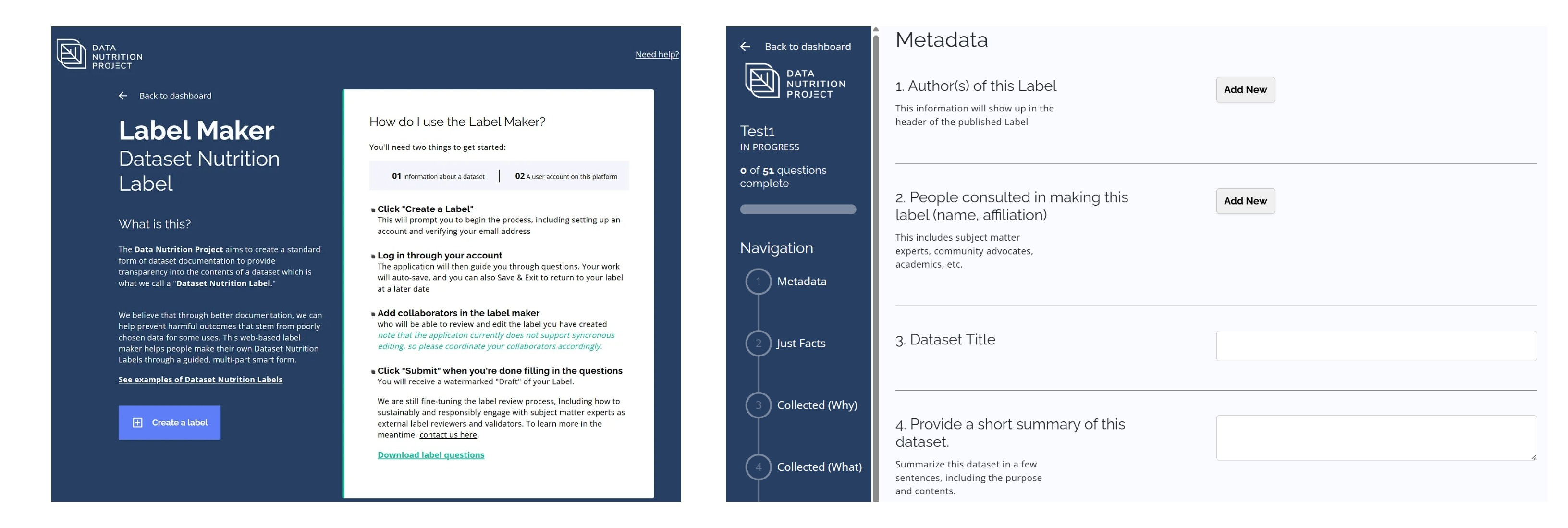
Introducing the LabelMaker Tool
The LabelMaker tool (accessible at labelmaker.datanutrition.org) operationalizes this approach by guiding users through the process of generating a Data Nutrition Label. Through a series of 51 questions, the tool will output a label for your dataset. The tool assists in documenting:
The origins and context of data collection.
Demographic and categorical coverage.
Critical limitations that could affect the dataset’s utility.
Preliminary recommendations for appropriate usage.
Although LabelMaker streamlines the documentation process and promotes clearer communication between technical and non-technical teams, it is important to recognize that the process relies on manual input and judgment. This inherent subjectivity means that the labels, while useful, are only a starting point for deeper data evaluation.
The third generation Dataset Nutrition Label now provides information about a dataset including its intended use and other known uses, the process of cleaning, managing, and curating that data, ethical and or technical reviews, the inclusion of subpopulations in the dataset, and a series of potential risks or limitations in the dataset. You may additionally want to read here about the second generation (2020) label, which informed the third generation label. [Source]
(Note: We’d love to eventually talk with folks from the Project to see just how far the labeling process has come (preprint), which would be valuable for those aspiring to build or contribute to similar efforts)
Who Should Use Data Nutrition Labels — and When
Data Nutrition Labels aren’t a tool just for data scientists. They are valuable for anyone involved in sourcing, building, evaluating, or releasing datasets, especially in interdisciplinary teams where not everyone speaks the same technical language. By providing a shared reference point, they help different roles align on what data is actually available, what risks come with it, and how to use it responsibly. The table below highlights where these labels are most helpful across the data lifecycle.

Labeling Benefits: Shoulda Put a Ring Label on It
Another approach: if you already painstakingly created a quality dataset and want others to easily use it and do good or valuable things with it, put effort into making it organized and ready for assessment by others. Perhaps idealism in the face of conventions like “Move Fast and Break Things”, or even “Move Fast and Be Responsible” — as Andrew Ng recently said during an Agentic AI talk —but, here we are.
Data Nutrition Labels offer several potential benefits, including:
Enhanced Transparency: By articulating what’s in a dataset, these labels help to surface issues that might otherwise go unnoticed.
Improved Communication: They create a common reference point for discussions between data practitioners and decision-makers.
Ethical Data Procurement: They support more thoughtful consideration when sourcing external data.
Audit & Management Readiness: Detailed documentation can aid in compliance and future reviews.
As we know, data isn’t neutral — datasets encode decisions about what matters, who matters, and how categories are drawn. Data Nutrition Labels offers space for these cultural fingerprints to be more visible, helping teams reflect critically on the cultural assumptions baked into their data.
However, it is crucial to acknowledge that these benefits are tempered by caveats. The labels depend on the quality of the underlying data and the thoroughness of the review process. They are most effective with structured data and may not translate well to unstructured information like text, images, or sensor outputs.

What they can’t fix: Data Label Limitations
The Data Nutrition Project and its LabelMaker tool mark an non-trivial move towards better data documentation, but they are not a panacea:
Manual Effort: The process requires considerable human judgment, which can lead to inconsistencies.
Scope Limitations: The framework is still evolving, particularly in addressing complex or unstructured data. (We are curious to see their latest efforts!)
Adoption Barriers: Since the approach is relatively new, integrating it into established workflows can be challenging and may require cultural shifts within organizations.

Recent & Future Developments: Members of the Data Nutrition Project have contributed to the CLeAR Documentation Framework

Wrapping Up the Nutrition Label
Data Nutrition Labels provide a thoughtful framework for beginning to understand the broader implications of data quality. They illuminate ethical and representational aspects that are often overlooked in traditional assessments. However, as a first step, they are necessarily limited. Organizations should view these labels as one component of a broader strategy for responsible data management—an evolving tool that invites further refinement and deeper critical engagement.
For those interested in exploring this approach further, additional resources and detailed guidelines are available at the Data Nutrition Project (datanutrition.org).
Have you used Data Nutrition Labels — or similar tools like Model Cards? What worked (or didn’t)? Share your thoughts in the comments, and subscribe to Data x Direction for more practical tools and critical takes at the intersection of data science, ethics, and leadership.
Bonus remark regarding recent news: within Kasia Chmielinski’s TED Talk, they mention that Big Tech companies scraping the web may run out of easily available internet information by 2026 (source?) Interesting to consider that OpenAI is now launching $20,000/month premium AI research bot options “designed to replace high-income professionals” - perhaps in efforts to turning profits, ahead of a potential data dry up Chmielinski mentioned?